23. Speicher - alles ist eine Liste#
Wie funktioniert der Arbeitsspeicher im Detail? Wie werden Daten in ihm abgelegt und wie gelangt die CPU zu diesen zu verarbeitenden Daten? Warum gibt es Datentypen? Wie manipulieren wir Daten die im Speicher liegen? Was sind und warum gibt es Speicheradressen und wie wird aus einem Speicherbereich eine Datenstruktur? Diesen Fragen wollen wir in diesem Abschnitt nachgehen.
Lernziel
Diese Übung bietet Ihnen eine Erklärung wie aus einer langen Liste aus Bits und Bytes, d.h. dem Arbeitsspeicher, Zahlen, Zeichen und Listen und andere Datentypen entstehen. Sie werden begreifen weshalb es Datentypen gibt und weshalb am Ende des Tages alle Daten durch eine lange Liste aus Zahlen realisiert werden.
Sie werden den Prozess der Abstraktion, von einer konkreten in eine abstrakte Welt, im Detail betrachten und dadurch besser verstehen.
Um ein tiefgreifendes Verständnis zu erwecken, reicht es uns nicht diese Fragen rein theoretisch zu beantworten. Stattdessen erarbeiten wir uns Antworten indem wir selbst Teile des Arbeitsspeicher und dessen Handhabung modellieren und implementieren. Dazu werden wir uns selbst, wie man salopp sagt, ins Knie schießen und uns zunächst stark einschränken.
Den Arbeitsspeicher modellieren wir durch eine Python-Liste, welche ausschließlich natürliche Zahlen von 0 bis 255, also 1 Byte, enthalten darf.
Warum modellieren wir den Speicher durch eine Python-Liste?
Bei genauer Betrachtung ist der Arbeitsspeicher nichts anderes als eine sehr sehr lange Liste.
Jeder 8-bit-Speicherbereich hat seine eigene eindeutige Adresse.
Der Befehlszeiger der Kontrolleinheit zeigt auf die aktuelle zu lesende / zu beschreibende Speicheradresse.
Der Inhalt wird in ein Register der CPU geladen und dort verarbeitet.
Zudem kann die CPU Ergebnisse an die Adresse des Befehlszeigers schreiben.
Aufgrund der Befehle, welche aus dem Arbeitsspeicher geladen werden, verändert die Kontrolleinheit den Befehlszeiger entsprechend, d.h., die Kontrolleinheit führt das im Speicher stehende Programm aus.
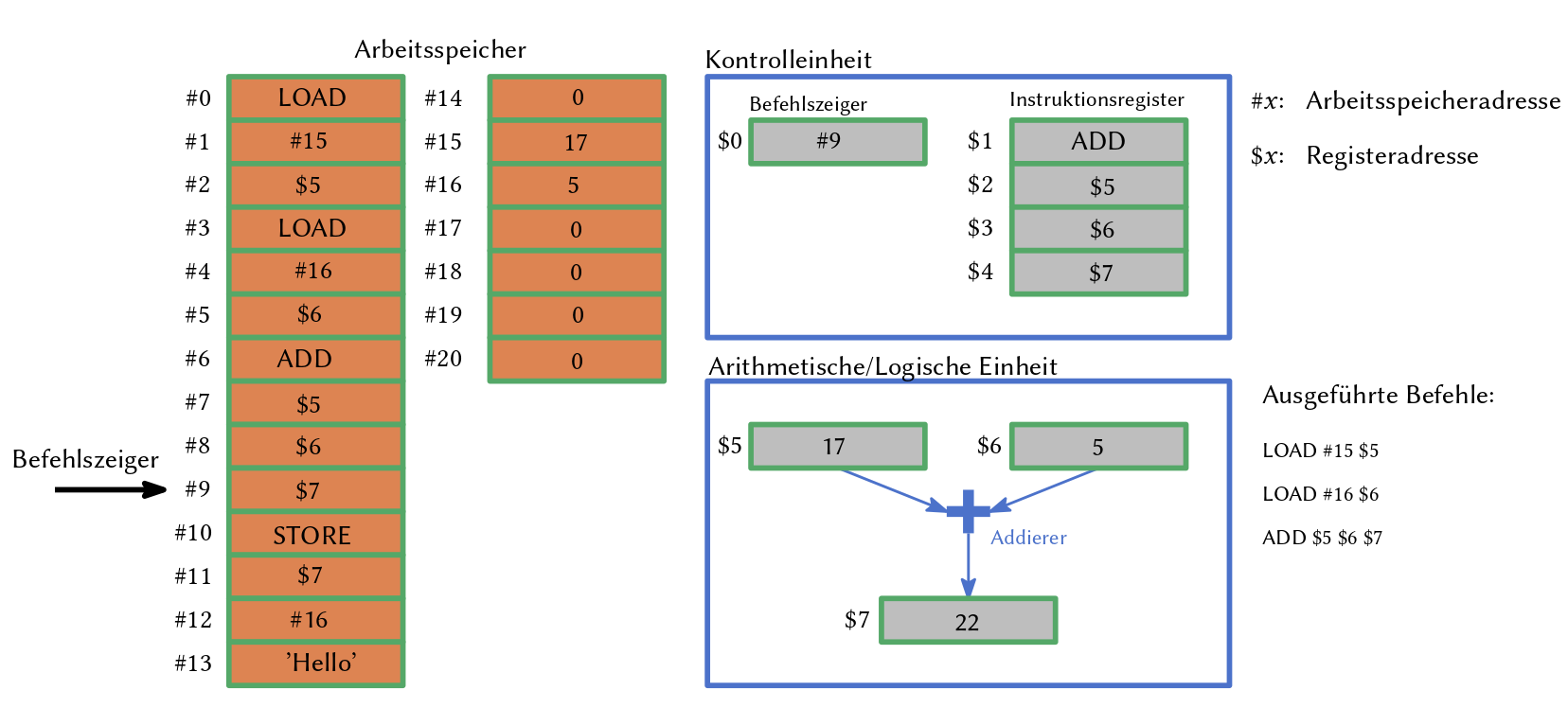
Abb. 23.1 Bereiche des Arbeitsspeichers (links) werden über eine Speicheradresse in Register der CPU (Kontrolleinheit und arithmetische/logische Einheit) geladen.#
Warum darf die Liste nur Zahlen enthalten? Der gesamte Computer arbeitet mit Zahlen in der Binärdarstellung. Dabei kann jeder Speicher des Computers nur eine endlich große Zahl aufnehmen, da Speicher bzw. dessen Bauteile endliche Ressourcen sind. Wir wählen die Dezimaldarstellung um es uns ein wenig einfacher und lesbarer zu gestalten.
Die CPU und deren Register werden wir nicht modellieren, deshalb gehen wir davon aus, dass in unserem Speicher nur Daten und keine Anweisungen bzw. Programme stehen.
Exercise 23.1 (Endlichkeit und reelle Zahlen)
Kann der Computer die Kreiszahl \(\pi\) als numerischen Wert im Speicher halten?
Solution to Exercise 23.1 (Endlichkeit und reelle Zahlen)
Nein! Die Kreiszahl \(\pi\) hat niedergeschrieben unendlich viele sich nicht wiederholende Nachkommastellen. Die Speicherressourcen eines Computers sind jedoch endlich.
Durch diese künstliche Einschränkung rücken wir näher an die konkrete Maschine heran. Daraufhin werden wir uns selbständig wieder von ihr entfernen. Dieser Prozess soll Ihnen aufzeigen, wie wir aus einer sehr konkreten Welt der Register, elektrischen Schaltungen und des endlichen Speichers, in eine abstrakte Welt der Datenstrukturen und Algorithmen gelangen. Dieser Prozess des Abstrahierens ist ein wesentlicher Bestandteil des Computational Thinkings und kann auf vielerlei Probleme angewendet werden.
Ihnen wird diese Übung möglicherweise sehr kleinlich und technisch vorkommen und damit liegen Sie richtig.
Die konkrete Welt ist kleinlich und technisch.
Programmieren Sie in Python bewegen Sie sich bereits in einer abstrakten Welt.
Vergleichen Sie Abbildung 10.1.
Jede Welt lässt sich jedoch weiter abstrahieren.
Für die Assembler-Programmierer*innen bietet C eine hohe Abstraktion und für die C-Programmierer*innen ist Python abstrakt.
Bauen Sie Programme mit Pyhton, so sind diese eine weitere Abstraktion.
Die Fähigkeit des Abstrahierens bleibt auf allen Ebenen essenziell.
Von wo aus wir mit der Abstraktion starten und wo wir hinaufsteigen, ist für das Lernen dieses Prozesses weniger wichtig.
Wichtig ist der Weg und den beschreiten wir hier!
23.1. Arbeitsspeicher als Python-Liste?#
23.1.1. Adressierung#
Werfen wir einen kurzen Blick auf die Eigenschaften und Funktionsweise des Arbeitsspeichers. Ignorieren wir den Cache, so greift die CPU direkt auf den Arbeitsspeicher zu. Ist unsere Rechnerarchitektur eine Von-Neumann-Architektur, so befinden sich im Arbeitsspeicher die gerade auszuführenden Anweisungen (das Programm) als auch die Daten die verarbeitet werden.
Der Arbeitsspeicher wird auch Random Access Memory genannt. Der Name betont, dass egal auf welche Speicherstelle die CPU zugreift (random access), dieser Zugriff in etwa die gleiche Zeit in Anspruch nimmt. Genauer gesagt eine bestimmte Anzahl an Zyklen. Diese Zeit ist viel viel kürzer als der Zugriff auf persistente Speicher, wie etwa die Festplatte.
Der Speicher ist unterteilt in 8-bit (1-byte) Bereiche. Wenn die CPU auf einen Speicherbereich zugreifen möchte, so adressiert sie diesen Bereich über eine Speicheradresse. Die Adresse, als auch der Inhalt des gesamten Speichers ist binär codiert.
Der Zugriff auf den Inhalt einer Python-Liste funktioniert ähnlich.
Auch hier greifen wir über eine Adresse auf einen Bereich, d.h. ein Listenelement, zu.
Diese Adresse nennen wir Index.
Sie ist eine Dezimalzahl welche zwischen 0 und (Länge der Liste - 1) liegt.
In einem Speicherbereich des Arbeitsspeicher stehen exakt 8 Bit, dies gilt für eine Python-Liste nicht.
Diese ist viel flexibler und kann allerart von Daten enthalten.
Modellieren wir unsere Speicheradressen als Listenindices und sind die Listenelemente natürliche Zahlen von 0 bis 255, so kommen wir schon sehr nah an die Beschränkungen bzw. Einfachheit des Arbeitsspeichers heran.
23.1.2. Primitive Datentypen#
In Python können wir bequem mit unterschiedlichen Datentypen umgehen.
Gewöhnlich unterteilt man Datentypen einer Programmiersprache in zwei Typen:
den primitiven und den
In Python gibt es jedoch keine primitive Datentypen.
Wie in Abschnitt Datentypen besprochen, ist jeder Datentyp in Python ein atomarer oder zusammengesetzter Datentyp!
In Java gibt es zum Beispiel folgende primitiven Datentypen:
ganzen Zahlen
byte(8-Bit)ganzen Zahlen
short(16-Bit)ganzen Zahlen
int(32-Bit)ganzen Zahlen
long(64-Bit)Zeichen
char(16-Bit)Fließkommazahlen
float(32-Bit)Fließkommazahlen
double(64-Bit)boolsche Werte
boolean(1-Bit)
Sie sehen, dass es für ganze Zahlen und Gleitkommazahlen mehrere Datentypen gibt, dessen Werte unterschiedlich viel Platz verbrauchen können.
Speicherverbrauch primitiver Datentypen
Der Speicherplatz, den ein Wert eines primitiven Datentyps verbraucht ist durch den Datentyp festgelegt und variiert nicht!
Obwohl es diese primitiven Datentypen in Python nicht gibt, stellen wir uns für diese Übung vor, dass auch alle atomaren Datentypen eine feste und bestimmte Anzahl an Bits verbrauchen (dies ist für int nicht wahr!).
Sie werden in fast allen anderen Sprachen mit primitiven Datentypen in Berührung kommen und auch in Python verhalten sich int, float und co. sehr ähnlich.
Zum Beispiel sind die Werte von atomaren Datentypen unveränderlich (engl. immutable).
Weshalb es diese Aufteilung gibt und wie aus Bits und Bytes verschiedene Datentypen entstehen erfahren sie in dieser Übung. Zusätzlich verweisen wir auf die Kapitel Datentypen (Grundlagen) und Datentypen (Fortsetzung).
Wie es möglich ist, dass wir in Python mit all den schönen Datentypen und Datenstrukturen hantieren können, werden wir uns nun Schritt für Schritt erarbeiten.
Wir werden uns in dieser Übung auf die Modellierung von Zahlen, Zeichen und Listen beschränken.
Wie der Titel dieser Übung suggeriert, ist alles eine Liste und so ist die Basis des Dictionary ebenfalls eine Liste. Wenn Sie erfahren wollen wie aus einer Liste ein Dictionary wird, empfehlen wir Ihnen das Kapitel Namensregister, insbesondere den Abschnitt Hashing und das Dictionary.
Exercise 23.2 (Speicherverbrauch von Fließkommazahlen)
Finden Sie heraus wie viel Speicher ein float Wert in Python verbraucht.
Solution to Exercise 23.2 (Speicherverbrauch von Fließkommazahlen)
Die Antwort hängt von Ihrem System und Ihrer Python-Version ab.
import sys
x = 1.313
sys.getsizeof(x)
import sys
x = 1.313
sys.getsizeof(x)
24
23.2. Modellierung des Arbeitsspeichers#
Wir wählen als Basis die Python-Liste und interpretieren den Index der Liste als Speicheradresse und den Listeneintrag als Speicherbereich.
Wir verzichten auf die Binärschreibweise und arbeiten stattdessen aus Gründen der Lesbarkeit mit Dezimalzahlen.
Jedoch soll auch für unsere Liste gelten, dass
sie nur Dezimalzahlen beinhalten darf und
diese durch 8 Bit darstellbar sind.

Abb. 23.2 Python-Liste von natürlichen Zahlen als Modell für den Arbeitsspeicher.#
Exercise 23.3 (Kapazität des Speicherbereichs)
Wie lautet die größte positive Dezimalzahl die wir in einem adressierbaren Speicherbereich, d.h., einem Listeneintrag halten können, sofern wir das Zweierkomplement als Codierung verwenden?
Solution to Exercise 23.3 (Kapazität des Speicherbereichs)
Die Zahl \(0111\, 1111_2\) in Binärschreibweise ist die größte positive die wir darstellen können. Binär ergibt dies \(0\,1000\,0000_2 - 1_2\) (binär) was wiederum gleich
(dezimal) ist.
Im Arbeitsspeicher eines Computers, der die Von-Neumann-Architektur realisiert, liegen Daten wie auch Anweisungen. Damit es nicht zu kompliziert wird, werden wir in dieser Übung uns nur auf die Daten konzentrieren und die Anweisungen außer acht lassen. Wir gehen also davon aus, dass die Kontrolleinheit (siehe Programmausführung) Ihre Befehle wie in der Harvard Architektur von einem anderen Speicher lädt. Diesen modellieren wir nicht.
Die Ausführung der Befehle simulieren wir als Python-Code, d.h. wir erlauben uns ganz normalen Python-Code für die Manipulation des Speichers zu schreiben.
Bedenken Sie jedoch, dass in der Realität dieser Code ebenfalls im Arbeitsspeicher stehen würde, dass Variablen in Register geladen werden müssten und if-Ausdrücke wie auch Schleifen durch Veränderungen des Befehlszeigers realisiert werden!
23.2.1. Initialisierung#
Der Arbeitsspeicher ist riesig, d.h., wir arbeiten mit einer großen Liste.
In seinem Initialzustand steht im flüchtige Speicher kein festgelegter Wert.
Wir initialisieren unseren Speicher mit lauter Nullen.
Den Speicher modellieren wir durch eine lange eindimensionale Liste namens memory.
Programme, die durch die CPU auf Speicherbereiche zugreifen, dürfen sich ihren Speicher nicht gegenseitig überschreiben bzw. in den Speicherbereich eines anderen Programms schreiben. Deshalb ist es notwendig Speicher zu reservieren und, da dieser endlich ist, wieder freizugeben.
Speicher allokieren
Das Reservieren von Speicherbereichen des Arbeitsspeicher nennen wir Allokation.
Woher wissen wir, wann ein Speicherbereich ungenutzt/frei bzw. genutzt/reserviert ist? Steht in einem Speicherbereich eine Null, deutet das erst einmal auf den Wert Null und nicht auf einen freien Bereich hin. Was wir brauchen ist eine Markierung die uns über den Zustand des Speicherbereichs allokiert oder frei informiert.
Wir könnten dafür eines der 8 Bit eines Speicherbereichs verwenden. Diese 1-Bit Markierung könnte anzeigen, dass dieser Speicherbereich nicht allokiert ist 1 oder frei 0. Dadurch könnten wir jedoch nur noch 128 verschiedene Zahlen pro Speicherbereich darstellen. Außerdem müssten wir dann immer wenn wir einen Speicherbereich nicht mehr verwenden, diese Zahl hineinschreiben.
Wir verwenden für die Markierung stattdessen eine zweite Liste inuse.
Exercise 23.4 (Speicherbelegung)
Wie könnte eine zweite Liste uns Aufschluss geben ob ein Speicherbereich in Verwendung ist oder nicht? Wie viel Speicher würde diese Liste benötigen?
Solution to Exercise 23.4 (Speicherbelegung)
Eine zweite Liste inuse[i] könnte durch einen boolschen Wert True oder False anzeigen, dass der Speicherbereich an der Stelle i allokiert ist oder nicht.
Jeder Eintrag braucht 1 Bit. Damit bräuchte die Liste \(n\) Bit, wobei \(n\) die Anzahl der Speicherbereiche (Länge der Liste) ist.
23.2.2. Datentypen#
Was sind Datentypen und weshalb brauchen wir diese?
In unserem Speicher memory befinden sich nur natürliche Zahlen von 0 bis 255.
Doch möchten wir natürlich auch Zeichen oder größere Zahlen repräsentieren.
Für interpretierte dynamisch getypte Sprachen wie Python (siehe Abschnitt Python’s Typisierung) benötigt der Interpreter Information darüber, wie er bestimmter Speicherbereich, d.h., ein Listenelement memory[i] zu interpretieren hat.
Datentypen liefern diese Information. Neben dem eigentlichen Wert beschreiben sie, wie dieser Wert zu interpretieren ist!
Da in memory nur Zahlen stehen können, ist auch diese Datentypinformation als Zahl codiert.
Brauchen wir dann nicht eine weitere Information die uns sagt, dass es sich bei diesem oder jenem Speicherbereich um die Datentypinformation handelt?
Wenn ja kommen wir aus dem Schlamassel nicht mehr heraus.
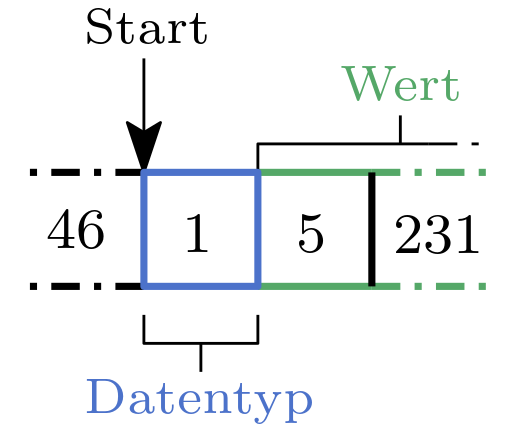
Abb. 23.3 (Datentyp, Wert)-Paar.#
Die Datentypinformation ist eine explizite Information, d.h. die Information wird niedergeschrieben.
Um zu entscheiden, ob ein Speicherbereich den Datentyp beschreibt, verwenden wir hingegen implizites Wissen/Information.
Wir einigen uns einfach darauf, dass ein Paar (Datentyp, Wert) mit dem Datentyp beginnt und dieser genau durch das erste Byte beschrieben wird.
Wenn wir wissen, dass ein solches Paar an der Adresse / Index i beginnt, können wir den Datentyp aus dem Speicherbereich memory[i] herauslesen.
Zu wissen, wo ein solches Paar beginnt, ist eine notwendige Voraussetzung.
Wir beschränken uns auf die folgenden Datentypen, wovon die Werte der primitiven Datentypen einen festen Speicherbedarf benötigen.
die natürlichen Zahlen, 16-Bit
Zeichen, 8-Bit
Speicheradressen, 16-Bit
Listen, variabler Speicherbedarf
(Zeichenketten, variabler Speicherbedarf)
Zeichenketten oder Listen sind von keinem primitiven Datentyp, denn sie haben eine variable Länge und können weiter zerlegt werden.
Die Festlegung des Speicherbedarfs für primitive Datentyp bedeutet auch, dass wir für kleine Zahlen, z.B., die 0 mehr Speicher verbrauchen als eigentlich notwendig.
Weshalb diese Lösung dennoch besser ist als einen variable Speicherbedarf zu verwalten wird gleich ersichtlich.
Jetzt wird Ihnen vielleicht auch klar warum es in Java und C/C++ verschiedene Datentypen für ganze Zahlen gibt.
Fassen wir noch einmal die impliziten und expliziten Informationen zusammen.
Explizite Information: Eine Zahl steht für einen bestimmten Datentyp:
0bedeutet, dass das was folgt eine natürlichen Zahl ist (wir verzichten auf negative Zahlen)1bedeutet, dass das was folgt ein Zeichen ist2bedeutet, dass das was folgt eine Liste ist3bedeutet, dass das was folgt eine Speicheradresse ist
Implizite Information: Jedes Objekt (Zahl, Buchstabe, Liste, Adresse) beginnt mit der Datentypinformation. Den Speicherbedarf je Datentyp nehmen wir ebenfalls implizit an.
23.2.2.1. Zeichenketten#
Haben wir nicht die Zeichenketten vergessen? Eine Zeichenkette ist nichts anderes als eine Liste von Zeichen und diese beiden Datentypen haben wir bereits berücksichtigt.
23.2.2.2. Zeichen#
256 unterschiedliche Zahlen, reichen uns aus um einfache Texte mit a-z, A-Z und die Sonderzeichen ., ,, ?, ! zu codieren.
Im Speicherbereich, der auf den Bereich des Datentyps (1) folgt, können wir demnach das Zeichen als Zahl hineinschreiben.
Mittels Codierung, welche uns für eine Zahl ein Zeichen ausspuckt (implizites Wissen), können wir einzelne Buchstaben in den Speicher schreiben und von diesem lesen.
Sie können sich Ihre eigene Codierung überlegen oder die Python-Funktionen ord und chr verwenden.
23.2.2.3. Natürliche Zahlen#
Wenn wir für Zahlen ebenfalls nur zwei Speicherbereiche (Datentyp und Wert) vorsehen, schränken wir uns zu sehr ein. Denn dann ist die größte Zahl die wir darstellen können die 255.
Exercise 23.5 (Ganze Zahlen auf Ihrem Computer)
Finden Sie heraus was die größte natürliche Zahl ist, die Ihr Computer (in Form eines primitiven Datentyps) abspeichern kann.
Wir legen fest, dass drei Speicherbereiche (einen für den Datentyp und zwei für den Wert) ausreichen. Das ist natürlich eine willkürliche Festlegung, für den Computer hat die Einschränkung hardwaretechnische Gründe.
Exercise 23.6 (Ganze Zahlen auf dem Computer)
Wie lautet die größte natürliche Zahl (nur der Wert), welche wir mit zwei Speicherbereichen also 2 Byte darstellen können?
Solution to Exercise 23.6 (Ganze Zahlen auf dem Computer)
Sollte jede Zahl zwei Speicherbereiche belegen? Wäre es nicht sinnvoll für kleine Zahlen lediglich einen Speicherbereich zu verwenden? Die Antwort hierfür lautet ja und nein. Das Ja ist offensichtlich: Wir sparen uns Speicher. Das Nein werden Sie gleich verstehen, wenn wir den Datentyp der Liste besprechen.
In der Realität führt man weitere Datentypen ein, z.B., gibt es in Java die folgenden Datentypen für ganze Zahlen:
long: 64-bitint: 32-bitshort: 16-bitbyte: 8-bit
In Python wird uns diese Entscheidung abgenommen bzw. werden ganze Zahlen so realisiert, dass es keine harte Grenze gibt!
Wie dies funktionieren kann werden Sie vielleicht auch verstehen, wenn wir die Listen-Realisierung besprechen.
Was passiert eigentlich wenn wir den Bereich der Darstellbarkeit überschreiten?
Exercise 23.7 (Überlauf von ganzen Zahlen)
Welcher Wert steht nach der Ausführung folgender Java-Codezeilen in der Variable z?
Sie können den Code zum Beispiel hier ausführen.
byte x = 127;
byte y = 1;
byte z = (byte)(x+y);
System.out.println(z);
Solution to Exercise 23.7 (Überlauf von ganzen Zahlen)
z enthält den Wert -128.
Da ein byte (eine 8 Bit) ganze Zahl statt natürliche Zahl repräsentiert, wird das höchste Bit als negativer Anteil interpretiert, siehe Abschnitt Ganze Zahlen Gleichung (7.4).
Ist dieses Bit gleich \(1\), so ist die Zahl negativ. Ist das Bit dagegen \(0\), so ist die Zahl positiv.
Da wir \(8\) Bits verwenden ist \(127_{10} = 0111 1111_2\) und \(1_{10} = 0000 0001_2\). Demnach gilt:
Was wiederum nach Gleichung (7.4)
ergibt. Es kommt zu einem unerwünschten Überlauf (engl. overflow).
Überlauf in Python
In Python haben Fließkommazahlen float ein hartes Limit, ganze Zahlen int jedoch nicht.
Ganze Zahlen int sind als sogenannte long integer objects implementiert, welche keine harte Grenze haben und damit zu keinem Überlauf führen.
Ganze Zahlen sind in Python keine primitiven Datentypen.
23.2.2.4. Speicheradressen#
Weshalb benötigen wir Speicheradressen als gesonderten Datentyp?
Wir klammern bei unserer Modellierung Anweisungen aus. Doch angenommen wir hätten derartige Anweisungen, dann würde, zum Beispiel, eine Addition darin bestehen die arithmetische Einheit der CPU anzuweisen zwei Zahlen, welche sich an einer bestimmten Speicheradresse befinden, zu addieren und das Ergebnis wieder an eine neue Speicheradresse zu schreiben. Da diese Anweisungen selbst im Arbeitsspeicher liegen, müssen auch die Speicheradresse im Arbeitsspeicher liegen.
Ein weiterer Grund erschließt sich, wenn wir den Datentyp der Liste besprechen. Überlegen Sie vielleicht schon einmal was wir durch eine Liste von Speicheradressen erzielen könnten?
Die Speicheradresse ist, wie erwähnt, nichts weiter als eine natürliche Zahl. Angenommen unser Speicher besteht aus \(n\) Byte. Um jeden Speicherbereich (jedes Byte) adressieren zu können müssen wir Zahlen von \(0\) bis \(n-1\) darstellen können. Damit ist die größtmögliche Speicheradresse eine harte Grenze für die Menge an Speicher!
Wir einigen uns, identisch zu den natürlichen Zahlen, auf einen Adressraum von 2 Byte.
Exercise 23.8 (Adressraum)
Wie groß kann unser Speicher sein, wenn wir 2 Byte für die Adressierung verwenden?
Recherchieren Sie wie groß der Adressraum Ihres Computers ist.
Solution to Exercise 23.8 (Adressraum)
Wir können \(2^{16} = 2^6 \cdot 2^{10} = 65536\) Byte also 64 KibiByte (KB) adressieren.
Auf einem 32-bit System können wir \(2^{32} = 2^2 \cdot 2^{30}\) Byte also 4 (GB) adressieren. Wenn Ihr Computer mehr als 4 GB Arbeitsspeicher hat befinden Sie sich auf einem 64-bit System. Auf einem 64-bit System könne wir \(2^{64} = 2^{34} \cdot 2^{30}\) also \(2^{34}\) (GB), das sind \(2^4 = 16\) ExiByte (EB) adressieren.
23.2.2.5. Listen#
Die wesentliche Eigenschaft einer Liste (wie auch des Arbeitsspeichers) ist, die schnelle Adressierung bei bekannter Adresse.
Kennen wir den Index i eines Wertes, so können wir auf den Wert in konstanter Laufzeit \(\mathcal{O}(1)\) zugreifen.
Wenn wir wissen, dass die Liste an einer bestimmten Speicheradresse j in unserem Arbeitsspeicher memory beginnt, welche Informationen benötigen wir um schnell auf das i-te Element der Liste zuzugreifen?
Falls jedes Element gleich viel Speicher einnimmt ist die Sache ganz einfach:
Wir müssen nur wissen wie viel Speicher jedes Element verbraucht!
Wenn eine Liste Elemente des gleichen Datentyps enthält, müssen wir den Datentyp auch nur einmal an den Anfang der Liste packen. Die Elemente selbst brauchen keine Information über ihren Datentyp!
Was noch fehlt ist die Länge der Liste.
Diese sollten wir mit abspeichern um testen zu können ob ein Index i überhaupt noch im Speicherbereich der Liste liegt.
Was ist diese Länge?
Sie ist eine natürliche Zahl!
Auch hier können wir uns den Datentyp schenken, da wir impliziert wissen, dass es eine natürliche Zahl ist!
Fassen wir zusammen: Unsere Liste beginnt mit dem Datentyp 2 (Liste) welcher 8 Bit belegt.
Es folgt die Länge der Liste als natürlichen Zahl ohne Datentypinformation.
Das sind weitere 16 Bit für den Wert.
Dann folgt der Datentyp der Listenelemente, was nochmals 8 Bit sind.
Nach dieser Prämisse folgen die eigentlichen Elemente ohne Datentypinformation.
Abbildung 23.4 fasst alle besprochenen Datentypen zusammen.
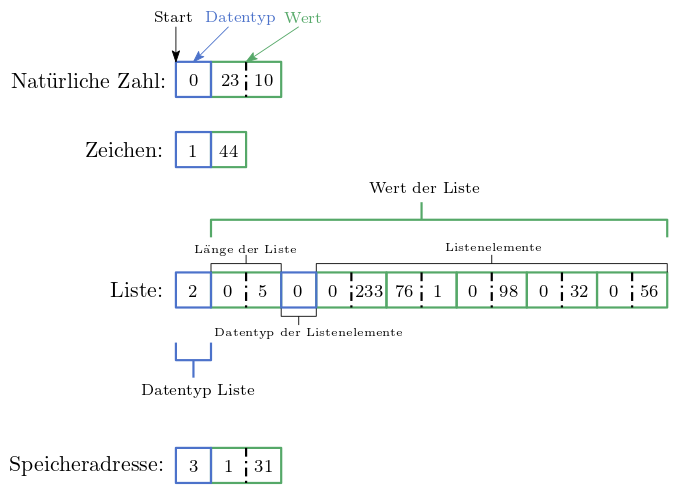
Abb. 23.4 Speicheranordnung von Werten verschiedener Datentypen. Die Liste ist eine Liste aus natürlichen Zahlen.#
Exercise 23.9 (Listen-Adressierung)
Angenommen jedes Listen-Element belegt 2 Speicherbereiche (2 Byte) und die Liste beginnt am Index
jinmemory. Wie lautet dann der Index vonmemorydesi-ten Elements der Liste?Wie viele Elemente kann eine Liste in unserem Fall maximal enthalten?
Solution to Exercise 23.9 (Listen-Adressierung)
Auf das gesuchte Element greifen wir durch
memory[4 + j + i * 2]zu.Die größte natürliche Zahl, die wir abspeichern können ist eine harte Grenze für die Länge der Liste, d.h., \(2^{16}-1\) Elemente.
Die schnelle und einfache Indexberechnung ist der Grund weshalb jedes Element eines primitive Datentyps gleich viel Speicher verbraucht. Dies ist ein ganz wesentliches Prinzip aller modernen Computer! Es vereinfacht bzw. beschleunigt die Adressierung.
Exercise 23.10 (Primitive Datentypen mit variablem Speicherverbrauch)
Angenommen wir hätten einen variablen Speicherverbrauch, d.h. kleinere Zahlen belegen weniger Speicher als große Zahlen. Wie müssten wir dann unsere Liste realisieren?
Solution to Exercise 23.10 (Primitive Datentypen mit variablem Speicherverbrauch)
Vor dem Wert der Zahl müsste deren Speicherbedarf stehen, also in unserem Beispiel ob die Zahl einen oder zwei Speicherbereiche belegt.
Da Zahlen unterschiedlich viele Speicherbereiche belegen, haben wir keine Möglichkeit durch die Adressen der Liste und dem Index des gesuchten Elements, auf dieses direkt zuzugreifen.
Das heißt, wir müssten die Liste von vorne nach hinten durchgehen bis wir am entsprechenden Index angelangt sind.
Aber moment!
In Python kann eine Liste unterschiedliche Datentypen enthalten.
Niemand verbietet mir z.B. folgende Liste zu definieren:
mylist = [1, 2, 'A', 'B', 3, 3.4131]
mylist
[1, 2, 'A', 'B', 3, 3.4131]
Wie funktioniert das denn? Bleiben Sie geduldig, auch das klären wir noch.
23.3. Implementierung#
23.3.1. Speicher initialisieren#
Realisieren wir zunächst einmal die Initialisierung.
Exercise 23.11 (Speicherinitialisierung)
Schreiben Sie eine Funktion initialize(n), die einen n-byte Speicher initialisiert.
Initialisieren Sie einen Speicher mit 1024 Byte.
Die Funktion soll zwei Listen memory und inuse zurückgeben.
def initialize(n):
memory = [0 for i in range(n)]
inuse = [False for i in range(n)]
return memory, inuse
memory, inuse = initialize(1024)
print(f'meomry = {memory}')
print(f'inuse = {inuse}')
meomry = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
inuse = [False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False]
Um mit dem Speicher hantieren zu können brauchen wir einige Hilfsfunktionen. Wir tasten uns im Folgenden in ganz kleinen Schritten nach vorne.
Exercise 23.12 (Valider Speicherbereich?)
Schreiben Sie folgende Hilfsfunktionen:
is_valid(addr, memory): Prüft ob eine Speicheradresseaddrim Speicherbereich liegt.is_free(addr, memory, inuse): Prüft ob eine Speicheradresse nutzbar ist (valide und frei).
def is_valid(addr, memory):
return addr >= 0 and addr < len(memory)
def is_free(addr, memory, inuse):
return is_valid(addr, memory) and not inuse[addr]
23.3.2. Speicherverwaltung für primitive Datentypen#
Stellen Sie sich vor wir haben wild und durcheinander in unserem Speicher geschrieben und möchten nun erneut in den Speicher etwas schreiben.
Wir müssten uns merken welche Speicherbereiche bereits belegt sind.
Das ist nicht gerade praktikabel.
Wie wäre es stattdessen wenn wir diese Aufgabe einer Funktion überlassen!
Dieser sagen wir wie viel Speicher wir gerne hätten und sie gibt uns eine entsprechende Speicheradresse zurück und setzt den benötigten Speicher auf inuse (Allokation).
Auch wäre es praktisch eine Art Umkehrfunktion dieser Operation zu haben. Also eine Funktion die den Speicher an einer bestimmten Adresse wieder freigibt.
Exercise 23.13 (Speicher statisch allokieren)
Schreiben Sie folgende Funktionen:
malloc(n_bytes, memory, inuse): Liefert eine Adresseaddrzurück, die auf einen neu allokierten Speicher vonn_bytesBytes zeigt.mfree(addr, n_bytes, memory, inuse): Gibtn_bytesBytes Speicher an der Adresseaddrfrei.
Da wir ständig mit Adressen, also natürlichen Zahlen hantieren, definieren wir uns zwei negative Zahlen, welche uns Auskunft über Erfolg oder Misserfolg der Operation geben sollen.
Immer dann wenn eine Funktion eine Adresse zurückliefert, jedoch etwas schief gegangen ist, geben wir ERROR_CODE anstatt der Adresse zurück.
Zum Beispiel könnte das der Fall sein, wenn der gesamte Speicher schon reserviert/allokiert wurde und wir noch mehr Speicher anfordern.
malloc geht von vorne bis hinten durch den Speicher durch und sucht nach genügend zusammenhängenden freien Bytes.
Das ist nicht sonderlich effektiv aber für unsere Zwecke ausreichend.
Nachdem diese zusammenhängenden Bytes gefunden wurden, setzten wir deren Markierung auf allokiert bzw. auf in Benutzung, d.h., inuse[i] = True.
mfree verändert nur die Markierungen und setzt diese auf frei.
ERROR_CODE = -1
SUCCESS_CODE = -2
def unfree(addr, n_bytes, memory, inuse):
for i in range(n_bytes):
if is_valid(addr+i, memory):
inuse[addr+i] = True
else:
return ERROR_CODE
return SUCCESS_CODE
def malloc(n_bytes, memory, inuse):
addr = 0
count = 0
for b in inuse:
if not b:
count += 1
else:
addr += count + 1
count = 0
if count == n_bytes:
if unfree(addr, n_bytes, memory, inuse):
return addr
else:
return ERROR_CODE
# return error code!
return ERROR_CODE
def mfree(addr, n_bytes, memory, inuse):
for i in range(n_bytes):
if is_valid(addr+i, memory):
inuse[addr+i] = False
else:
return ERROR_CODE
return SUCCESS_CODE
Lassen Sie uns das doch einmal austesten:
memory, inuse = initialize(1024)
print(malloc(8, memory, inuse)) # 0
print(malloc(15, memory, inuse)) # 0 + 8 = 8
print(malloc(8, memory, inuse)) # 8 + 15 = 23
print(mfree(0, 8, memory, inuse)) # free bytes 0,1,...,7
print(malloc(8, memory, inuse)) # allocate bytes 0,1,...,7 again => 0
0
8
23
-2
0
Bringen wir für die Allokierung und Deallokierung (Speicher freigeben) die Datentypen ins Spiel. Wäre es nicht äußerst praktikabel Code in der folgenden Art schreiben zu können:
x = alloc(data_type = 0, value=50) # x = 50
y = alloc(data_type = 0, value=1000) # y = 1000
z = add(x, y) # z = x + y
free(x)
free(y)
Dieser Code allokiert zwei Speicherbereiche für jeweils eine natürliche Zahl und initialisiert diese mit 50 bzw. 1000.
Dann addieren wir die zwei Zahlen die im Speicher an der Adresse x und y stehen und schreiben das Ergebnis nach z, wobei z automatisch reserviert wird.
Schlussendlich geben wir die beiden Speicherbereiche bei x und y frei.
Dieser Code sieht fast schon so aus wie unser üblicher Python-Code.
Das verwundert nicht denn hinter einer Zuweisung
x = 50
steckt eine Speicherallokation und eine Variable x ist nichts anderes als ein Zeiger, d.h. eine Speicheradresse die auf den Speicherbereich zeigt, der den Wert 50 enthält.
Python und andere Hochsprachen nehmen uns diese Speicherorganisation ab.
Wir müssen Speicher auch nicht freigeben, auch darum kümmert sich Python automatisch.
Die Funktion free(addr) ist nicht ganz leicht zu implementieren, denn wir müssen anhand des Datentyps an der Speicheradresse addr feststellen wie viel Bytes wir freigeben müssen.
Das ist für Listen besonders trickreich.
Lassen wir Listen deshalb zunächst außer acht.
Exercise 23.14 (Speicher dynamisch allokieren)
Schreiben Sie zunächst folgende einfache Hilfsfunktionen:
number_to_byte(number): Wandelt eine natürliche Zahl in 2 Bytes um.to_number(byte1, byte2): Wandelt 2 Bytes in eine natürliche Zahl um.char_to_byte(char): Wandelt ein Zeichen in ein Byte um.to_char(byte): Wandelt ein Byte in ein Zeichen um.
Daraufhin definieren Sie folgende Funktionen zur Speicherverwaltung:
calc_bytes(data_type): Berechnet die Anzahl an Bytes, welche ein Wert vom Typdata_typeverbraucht.alloc(data_type, value, memory, inuse): Liefert eine Adresseaddrzurück, die auf einen neu reservierten Speicher zeigt und schreibt den Wertvaluegleich an die richtige Stelle.free(addr, memory, inuse): Gibt den Speicher anaddrfrei.
Hinweis: Lassen Sie Listen in diesem Schritt außer acht, um diese kümmern wir uns gleich. free enthält keine Informationen darüber wie viel Speicher freigegeben wird. Diese Information erhalten Sie durch die Datentypen, also durch calc_bytes.
name_to_data_type = {'number': 0, 'char': 1, 'list': 2, 'addr': 3}
def to_data_type(name):
if name in name_to_data_type:
return name_to_data_type[name]
else:
return ERROR_CODE
def number_to_byte(number):
return (number // 256, number % 256)
def to_number(byte1, byte2):
return byte1 * 256 + byte2
def char_to_byte(char):
return ord(char)
def to_char(byte):
return chr(byte)
def calc_bytes(data_type):
if data_type == to_data_type('number'):
return 3
if data_type == to_data_type('char'):
return 2
if data_type == to_data_type('addr'):
return 3
return ERROR_CODE
def alloc(data_type, value, memory, inuse):
n_bytes = calc_bytes(data_type)
if n_bytes == ERROR_CODE:
return ERROR_CODE
addr = malloc(n_bytes, memory, inuse)
if addr != ERROR_CODE:
memory[addr] = data_type
if data_type == to_data_type('number') or data_type == to_data_type('addr'):
byte_value = number_to_byte(value)
memory[addr+1] = byte_value[0]
memory[addr+2] = byte_value[1]
if data_type == to_data_type('char'):
memory[addr+1] = char_to_byte(value)
return addr
def free(addr, memory, inuse):
if is_valid(addr, memory):
data_type = memory[addr]
n_bytes = calc_bytes(data_type)
return mfree(addr, n_bytes, memory, inuse)
return ERROR_CODE
Lassen Sie uns das doch einmal austesten:
memory, inuse = initialize(1024)
print(alloc(to_data_type('number'), 4, memory, inuse)) # 0
print(alloc(to_data_type('number'), 130, memory, inuse)) # 0 + 3 = 3
print(to_number(memory[3+1], memory[3+2])) # 130
print(alloc(to_data_type('char'), 'A', memory, inuse)) # 3 + 3 = 6
print(alloc(to_data_type('char'), 'C', memory, inuse)) # 6 + 2 = 8
print(free(0, memory, inuse)) # free bytes 0,1,...,24 => -2 == SUCCESS
print(alloc(to_data_type('number'), 6, memory, inuse)) # allocate bytes 0,1,2,3 again => 0
0
3
130
6
8
-2
0
23.3.3. Addieren im Speicher#
Um zwei Zahlen im Speicher zu addieren fehlt uns nur noch eine Funktion die zwei Zahlen an zwei Speicheradressen liest und das Ergebnis der Addition an eine neu reservierte Speicheradresse schreibt. Diese neue Adresse sollte die Funktion zurückgeben.
def read_number(addr, memory):
return to_number(memory[addr+1], memory[addr+2])
def add(addr1, addr2, memory, inuse):
number1 = read_number(addr1, memory)
number2 = read_number(addr2, memory)
# % (256**2) erzeugt den Überfluss (Overflow) falls die Zahlen zu groß werden!
value = (number1 + number2) % (256**2)
addr = alloc(to_data_type('number'), value, memory, inuse)
return addr
Lassen Sie uns nun endlich die Addition über unseren Speicher durchführen:
memory, inuse = initialize(1024) # fresh memory
x = alloc(to_data_type('number'), 50, memory, inuse) # x = 50
y = alloc(to_data_type('number'), 1000, memory, inuse) # y = 1000
z = add(x, y, memory, inuse) # z = x + y
free(x, memory, inuse)
free(y, memory, inuse)
print(read_number(z, memory)) # 1050
1050
23.3.4. Speicherverwaltung für Listen#
Was fehlt ist alloc und free für eine Liste.
Was wir benötigen ist die Berechnung des Speicherbedarfs einer Liste.
Betrachten Sie Abbildung 23.5.
Wir berechnen den Speicherbedarf einer Liste durch
4 + n * (calc_byte(memory[addr+3])-1)
wobei n die Anzahl der Listenelemente ist.
Weshalb subtrahieren wir die eins?
Da Listenelemente keine Datentypinformation benötigen!
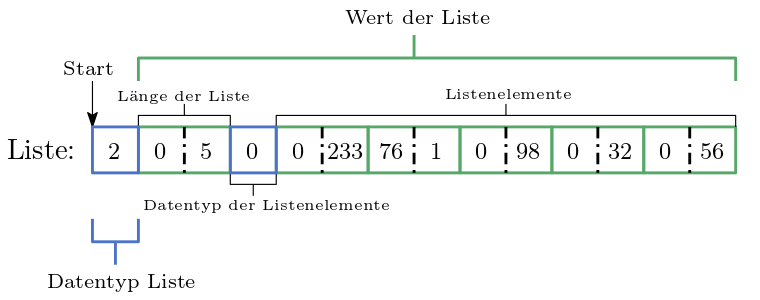
Abb. 23.5 Liste wie sie im Speicher liegt. Um den Speicherbedarf zu berechnen benötigen wir die Länge der Liste, und den Datentyp der Listenelemente.#
Exercise 23.15 (Speicher für Listen allokieren)
Schreiben Sie eine Funktion calc_list_bytes(addr, memory), welche den benötigten Speicherbereich einer Liste, welche an Adresse addr startet, berechnet.
Bauen Sie diese Funktion in free ein.
Schreiben Sie eine weitere Funktion alloc_list(data_type, n, memory, inuse) die Speicher für eine Liste reserviert, wobei data_type der Datentyp der Listenelemente und n die Anzahl der Listenelemente ist.
Hinweis: Sie müssen die natürliche 2-byte Zahl in eine herkömmliche Dezimalzahl umwandeln. Hierfür empfiehlt sich die Hilfsfunktion to_number(byte1, byte2).
def calc_list_bytes(addr, memory):
m = to_number(memory[addr+1], memory[addr+2])
n_bytes_element = calc_bytes(memory[addr+3]) - 1
return 4 + m * n_bytes_element
def alloc_list(data_type, n, memory, inuse):
n_bytes = 4 + (calc_bytes(data_type)-1) * n
if data_type == to_data_type('list'):
return ERROR_CODE
# 1. alloc memory
addr = malloc(n_bytes, memory, inuse)
# 2. initalize meta data (data type of the list and its elements and length of the list)
memory[addr] = to_data_type('list')
n_bytes = number_to_byte(n)
memory[addr+1] = n_bytes[0]
memory[addr+2] = n_bytes[1]
memory[addr+3] = data_type
return addr
def free(addr, memory, inuse):
if is_valid(addr, memory):
data_type = memory[addr]
if data_type == to_data_type('list'):
n_bytes = calc_list_bytes(addr, memory)
else:
n_bytes = calc_bytes(data_type)
return mfree(addr, n_bytes, memory, inuse)
return self.ERROR_CODE
Falls wir eine Liste allokieren
length = 10
mylist = alloc_list(to_data_type('number'), length, memory, inuse)
mylist
9
ist diese unbefüllt und wir können mit ihr noch nichts anfangen. Wir benötigen Funktionen für den Zugriff.
Exercise 23.16 (Listenverwaltung)
Schreiben Sie folgende Funktionen zur Verwaltung einer Liste:
list_len(addr, memory, inuse): Gibt die Länge der Liste zurück.set_list_value(addr, index, value, memory, inuse): Setzt den Wertvaluean die Positionindexder Liste, die anaddrbeginnt.get_list_value(addr, index, memory, inuse): Gibt das Listenelement an der Stelleindexder Liste zurück.
def list_len(addr, memory, inuse):
return to_number(memory[addr+1], memory[addr+2])
def set_list_value(addr, index, value, memory, inuse):
data_type = memory[addr+3]
m = calc_bytes(data_type)-1
mem_addr = addr + 4 + (m * index)
if data_type == to_data_type('number') or data_type == to_data_type('addr'):
byte_value = number_to_byte(value)
memory[mem_addr] = byte_value[0]
memory[mem_addr+1] = byte_value[1]
return SUCCESS_CODE
elif data_type == to_data_type('char'):
memory[mem_addr] = char_to_byte(value)
return SUCCESS_CODE
else:
return ERROR_CODE
def get_list_value(addr, index, memory, inuse):
data_type = memory[addr+3]
m = calc_bytes(data_type)-1
mem_addr = addr + 4 + (m * index)
if data_type == to_data_type('number') or data_type == to_data_type('addr'):
return to_number(memory[mem_addr], memory[mem_addr+1])
elif data_type == to_data_type('char'):
return to_char(memory[mem_addr])
else:
return ERROR_CODE
Lassen Sie uns eine Liste mit den Quadratzahlen von 1 bis einschließlich 10 erzeugen und zur Überprüfung wieder Ausgeben:
memory, inuse = initialize(1024)
length = 10
mylist = alloc_list(to_data_type('number'), length, memory, inuse)
list_len(mylist, memory, inuse)
# fill list
for i in range(length):
set_list_value(mylist, i, (i+1)**2, memory, inuse)
# read from list
for i in range(length):
print(get_list_value(mylist, i, memory, inuse))
n_allocated_bytes = len([e for e in inuse if e])
print(f"We allocated {n_allocated_bytes} bytes")
# 24 Byte (4 + 10 * 2)
print(f"Our list in mememory: {memory[0:n_allocated_bytes]}")
1
4
9
16
25
36
49
64
81
100
We allocated 24 bytes
Our list in mememory: [2, 0, 10, 0, 0, 1, 0, 4, 0, 9, 0, 16, 0, 25, 0, 36, 0, 49, 0, 64, 0, 81, 0, 100]
23.3.5. Mehrdimensionale Listen#
Wenn Sie alloc_list betrachten werden Sie feststellen, dass eine Liste aus Elementen vom Datentyp to_data_type('list') nicht zulässig ist.
Unsere Liste darf derzeit nur primitive Datentypen (natürliche Zahlen, Zeichen und Adressen) beinhalten.
Mehrdimensionale Listen aus Elementen eines primitiven Datentyps lassen sich recht einfach erstellen, wenn wir anstatt einer Länge, für jede Dimension eine Länge anfügen. Eine solche Liste würde anstatt einer Länge eine Liste aus Längen beinhalten. Zudem würden wir die Elemente immernoch linear nebeneinander anordnen.
Nehmen wir zum Beispiel an, wir möchten eine zweidimensionale Liste erzeugen, wobei die erste Dimension die Länge \(n\) und die zweite die Länge \(m\) hat.
Die Liste two_dim_list enthält demnach
Elemente. Das Element two_dim_list[i][j] hat den linearen Index
und der lineare index \(k\) lässt sich wie folgt in einen zweidimensionalen Index umrechnen:
Es gibt aber noch eine andere Möglichkeit mehrdimensionale Listen zu realisieren. Diese bietet uns zugleich eine Möglichkeit Listen mit Elementen mit unterschiedlichen Datentypen zu erstellen. Haben Sie eine Idee wie wir das erreichen können?
Exercise 23.17 (Listen und Zeiger)
Wie können wir Listen mit Elementen mit unterschiedlichen Datentypen realisieren?
Tipp: Denken Sie an den Datentyp, den wir bis jetzt noch gar nicht verwendet haben.
Solution to Exercise 23.17 (Listen und Zeiger)
Wir können Adressen (Zeiger) als Listenelemente verwenden. Diese Adressen können auf unterschiedliche primitive Datentypen aber auch andere Listen zeigen!
Folgender Code erzeugt die gleiche Ausgabe wie zuvor, doch liegen die Quadratzahlen irgendwo verteilt im Speicher memory.
Deren Adressen sind jedoch in der Liste enthalten.
Die Speicherverwaltung wird dadurch komplexer.
memory, inuse = initialize(1024)
length = 10
mylist = alloc_list(to_data_type('addr'), length, memory, inuse)
list_len(mylist, memory, inuse)
print(f"We allocated {len([e for e in inuse if e])} bytes")
# fill list with pointers
for i in range(10):
# pointer to the number (i+1)**2
addr = alloc(to_data_type('number'), (i+1)**2, memory, inuse)
set_list_value(mylist, i, addr, memory, inuse)
# read from list
for i in range(length):
# read pointer
addr = get_list_value(mylist, i, memory, inuse)
# read the number at the pointer
print(read_number(addr, memory))
print(f"We allocated {len([e for e in inuse if e])} bytes")
We allocated 24 bytes
1
4
9
16
25
36
49
64
81
100
We allocated 54 bytes
Wenn wir den gesamten Speicher wieder freigeben wollen, reicht es nicht nur den Speicher der Liste freizugeben. Wir müssen auch den Speicher an den Adressen der Liste freigeben. Dabei müssen wir sicher sein, dass kein anderer noch verwendeter Zeiger auf das Element zeigt!
# 54 Bytes
print(f"We allocated {len([e for e in inuse if e])} bytes")
# deep free of the memory
for i in range(10):
addr = get_list_value(mylist, i, memory, inuse)
free(addr, memory, inuse)
# 24 Bytes
print(f"We allocated {len([e for e in inuse if e])} bytes")
free(mylist, memory, inuse)
# 0 Bytes
print(f"We allocated {len([e for e in inuse if e])} bytes")
We allocated 54 bytes
We allocated 24 bytes
We allocated 0 bytes
All das übernimmt in Python der sogenannte Garbage Collector.
Garbage Collector (Python)
Der Garbage Collector bezeichnet eine automatische Speicherverwaltung, die zur Vermeidung von Speicherproblemen beiträgt und zur Laufzeit nicht länger benötigte Speicherbereiche automatisch freigibt. Der Vorteil wird mit einem erhöhten Ressourcenverbrauch erkauft.
23.3.6. Ein einfacher Parser#
Um die Manipulationen im Speicher besser nachzuvollziehen zu können wäre es großartig eine Funktion mem_to_string(addr, memory, inuse) zu haben, welche einen primitiven Datentyp oder eine Liste in einer gut leserliche Zeichenkette umwandelt.
An einer Adresse ADDR kann sich eine andere ADDR, eine Zahl number, ein Zeichen char oder eine Liste LIST befinden.
Eine Liste LIST kann wiederum natürliche Zahlen number, Zeichen char oder Adressen ADDR enthalten.
Diese Struktur ist eine von uns definierte Syntax!
Was wir benötigen ist ein Programm (in unserem Fall nur eine Funktion), welche diese Syntax versteht und umwandelt – wir brauchen einen Interpreter.
Ein solches Programm nennt man Parser.
Parser
Ein Parser wandelt eine Struktur (z.B. Datenstruktur oder eine Zeichenkette) in eine andere Struktur um. Die Syntax der Quell- und Zielstruktur sind oft durch eine Grammatik definiert.
Um unsere Syntax zu definieren nutzten wir eine sog. Grammatik mit den folgenden Ableitungsregeln:
ADDR->ADDR | number | char | LISTLIST->[ (ADDR, ..., ADDR) | (number, ..., number) | (char, ..., char) ]
Das was links vom Ableitungspfeil steht, kann durch das was rechts vom Pfeil steht ersetzt werden.
Eine Adresse ADDR kann auf eine weitere Adresse ADDR, eine Zahl number, ein Zeichen char oder eine Liste LIST verweisen.
Handelt es sich um eine Zahl oder ein Zeichen, können wir dieses ausgeben.
Verweist die Adresse auf eine Adresse, springen wir zu dieser Adresse und fahren fort.
Verweist die Adresse auf eine Liste, geben wir [ aus und iterieren durch jedes Element der Liste.
Handelt es sich bei einem Listenelement um eine Zahl oder ein Zeichen, geben wir dieses aus.
Handelt es sich um eine Adresse verfahren wir entsprechend weiter.
Nachdem wir durch eine Liste iteriert sind, geben wir ] aus.
Da unsere Syntax rekursiv definiert ist, eignet sich auch eine rekursive Funktion um die Ausgabe zu erzeugen.
Exercise 23.18 (Rekursive Ausgabe)
Implementieren Sie eine Funktion mem_to_string(addr, memory, inuse), die eine geeignete Zeichenkette des an der Adresse addr liegenden Elements zurückliefert.
def char_to_str(addr, memory):
return to_char(memory[addr+1])
def number_to_str(addr, memory):
return str(to_number(memory[addr+1], memory[addr+2]))
def list_to_str(mylist, memory, inuse):
output = "["
length = list_len(mylist, memory, inuse)
element_data_type = memory[mylist+3]
for i in range(length):
value = get_list_value(mylist, i, memory, inuse)
if element_data_type == to_data_type('addr'):
output += mem_to_string(value, memory, inuse)
elif element_data_type == to_data_type('char'):
output += value
elif element_data_type == to_data_type('number'):
output += str(value)
if i < length-1:
output += ", "
output += "]"
return output
def mem_to_string(addr, memory, inuse):
output = ""
if is_valid(addr, memory) and inuse[addr]:
data_type = memory[addr]
if data_type == to_data_type('char'):
output += char_to_str(addr, memory)
elif data_type == to_data_type('number'):
output += number_to_str(addr, memory)
elif data_type == to_data_type('list'):
output += list_to_str(addr, memory, inuse)
elif data_type == to_data_type('addr'):
new_addr = read_number(addr, memory)
output += mem_to_string(new_addr, memory, inuse)
return output
Betrachten wir zunächst mem_to_string.
Für unsere natürlichen Zahlen und Zeichen ist die Sache klar.
Für Sie transformieren wir den Wert im Speicher gegeben durch addr in eine Zeichenkette.
Das übernehmen die Funktionen char_to_str und number_to_str.
Handelt es sich hingegen um eine Adresse holen wir ebenfalls den Wert der Adresse new_addr aus dem Speicher.
Wir sind wieder am Ausgangspunkt, d.h. wir haben erneut eine Adresse new_addr und möchten den Wert, der an dieser Adresse steht, in eine schön formatierte Zeichenkette umwandeln.
Demnach rufen wir mem_to_string mit dieser neuen Adresse new_addr auf.
Würde an der neuen Adresse erneut eine Adresse stehen würden wir den Vorgang wiederholen und zwar solange bis an der Adresse keine neue Adresse mehr steht.
Bleibt noch der Fall der Liste.
Wenn der Datentyp an der Adresse addr eine Liste ist, wandeln wir diese Liste durch list_to_str in eine Zeichenkette um.
Glücklicherweise können wir unsere zuvor definierten Hilfsfunktionen list_len und get_list_value nutzen.
Die Zeichenkette lassen wir mit einem "[" beginnen um den Anfang der Liste zu markieren.
Durch list_len holen wir die Längeninformation der Liste aus dem Speicher.
Anhand unserer Listendefinition in Abbildung 23.5, wissen wir dass an memory[mylist+3] der Datentyp der Listenelemente der Liste steht.
Was folgt ist eine Iteration über die Listenelemente.
get_list_value liefert uns je ein Listenelement.
Erneut ist der Fall für die Zahlen und Zeichenketten klar.
get_list_value holt den Wert aus dem Speicher, diesen wandeln wir in eine Zeichenkette um.
Für eine Adresse gilt das gleiche und wir haben bereits eine Funktion die diese Aufgabe übernehmen kann.
Sie heißt mem_to_string!
An dieser Stelle setzten wir erneut auf die Rekursion.
Wir trennen jedes Listenelement durch ", " und fügen am Ende noch die geschlossene Klammer "]" an, um das Ende der Liste zu markieren.
Die beiden rekursiven Funktionsaufrufe ergeben sich aus der beschriebenen Syntax. Im ersten Fall aus
ADDR -> ADDR
und im zweiten Fall aus
ADDR -> LIST -> (ADDR, ..., ADDR).
Durch mem_to_string haben wir eine Möglichkeit um zu testen ob unsere definierten Funktionen auch das gewünschte Ergebnis erzeugen und unser Speicher memory so manipuliert wird, wie wir uns das gedacht haben.
Zum Beispiel können wir nun unsere Variablen durch mem_to_string Ausgeben:
memory, inuse = initialize(1024)
x = alloc(to_data_type('number'), 4, memory, inuse)
y = alloc(to_data_type('number'), 130, memory, inuse)
z = add(x, y, memory, inuse)
char1 = alloc(to_data_type('char'), 'A', memory, inuse)
char2 = alloc(to_data_type('char'), 'B', memory, inuse)
# 4 + 130 = 134
print(f"{mem_to_string(x, memory, inuse)} + {mem_to_string(y, memory, inuse)} = {mem_to_string(z, memory, inuse)}")
# A
print(mem_to_string(char1, memory, inuse))
# B
print(mem_to_string(char2, memory, inuse))
4 + 130 = 134
A
B
23.3.7. Listen erzeugen#
Wie Sie oben sehen, können wir durch alloc bereits sehr bequem mit primitiven Datentypen umgehen.
Um eine Liste zu erstellen haben wir noch keine solche Hilfsfunktion implementiert.
Wäre es nicht toll wenn wir durch folgenden Code eine neue Liste aus Zahlen oder Zeichen an die Adresse numbers bzw. chars schreiben könnten?
numbers = new_primitive_list([1,2,3,4,5], to_data_type('number'), memory, inuse)
chars = new_primitive_list("Hello World", to_data_type('char'), memory, inuse)
Exercise 23.19 (Listen für primitive Datentypen erzeugen)
Implementieren Sie die Funktion new_primitive_list(values, data_type, memory, inuse).
Verwenden Sie hierfür alloc_list und set_list_value.
values enthält die Werte der Liste, wobei diese entweder ausschließlich Zahlen oder Zeichen sind.
def new_primitive_list(values, data_type, memory, inuse):
length = len(values)
mylist = alloc_list(data_type, length, memory, inuse)
# fill list
for i in range(length):
set_list_value(mylist, i, values[i], memory, inuse)
return mylist
numbers = new_primitive_list([1,2,3,4,5], to_data_type('number'), memory, inuse)
chars = new_primitive_list("Hello World", to_data_type('char'), memory, inuse)
print(mem_to_string(numbers, memory, inuse))
print(mem_to_string(chars, memory, inuse))
[1, 2, 3, 4, 5]
[H, e, l, l, o, , W, o, r, l, d]
Durch unsere Funktionen bauen wir an einer Welt, welche wir immer besser manipulieren können. Gehen wir noch einen Schritt weiter! Wäre es nicht wundervoll, wenn folgender Code funktionieren würde:
new_list([1, 2, 'A', [[1, 2], 3, 4], "Hello World"], memory, inuse)
Exercise 23.20 (Listen erzeugen)
Implementieren Sie die gewünschte Funktion new_list(values, memory, inuse).
Sie müssen dabei für jeden Eintrag in values den Datentyp berechnen.
Verwenden Sie alloc_list, alloc und set_list_value.
Hinweise:
Da Ihre Liste weitere Listen enthalten kann werden Sie vermutlich auf die Rekursion zurückgreifen müssen.
Da Ihre Listen gemischte Datentypen enthalten, sollten Sie Zeiger / Adressen verwenden.
Wir haben eine kleine Hilfsfunktion get_data_type(value) geschrieben, die uns den Datentyp anhand des Wertes value bestimmt.
Wichtig dabei ist, dass eine Zeichenkette mit Länge gleich 1 ein char ist, wobei eine Zeichenkette mit Länger > 1 eine Liste (aus char) ist!
def get_data_type(value):
if type(value) == int:
return to_data_type('number')
if type(value) == str:
if len(value) == 1:
return to_data_type('char')
else:
return to_data_type('list')
def new_list(values, memory, inuse):
length = len(values)
mylist = alloc_list(to_data_type('addr'), length, memory, inuse)
for i in range(length):
element_data_type = get_data_type(values[i])
if element_data_type in [to_data_type('number'), to_data_type('char')]:
addr = alloc(element_data_type, values[i], memory, inuse)
else:
addr = new_list(values[i], memory, inuse)
set_list_value(mylist, i, addr, memory, inuse)
return mylist
memory, inuse = initialize(1024)
numbers = new_list([1,2,"Hello World",4,5], memory, inuse)
chars = new_list("Hello World", memory, inuse)
# [1, 2, [H, e, l, l, o, , W, o, r, l, d], 4, 5]
print(mem_to_string(numbers, memory, inuse))
# [H, e, l, l, o, , W, o, r, l, d]
print(mem_to_string(chars, memory, inuse))
mylist = new_list([1, 2, 'A', [[1, 2], 3, 4], "Hello World"], memory, inuse)
# [1, 2, A, [[1, 2], 3, 4], [H, e, l, l, o, , W, o, r, l, d]]
print(mem_to_string(mylist, memory, inuse))
[1, 2, [H, e, l, l, o, , W, o, r, l, d], 4, 5]
[H, e, l, l, o, , W, o, r, l, d]
[1, 2, A, [[1, 2], 3, 4], [H, e, l, l, o, , W, o, r, l, d]]
Durch unsere zuvor definierten Hilfsfunktionen ist new_list zwar immernoch eine Herausforderung aber stellen Sie sich einmal vor wir hätten keine der Hilfsfunktionen zuvor definiert.
Die Dekomposition des Problems in viele kleinere Probleme hilft uns ungemein beim Lösen des Gesamtproblems.
23.3.8. Ende der Reise#
An dieser Stelle beenden wir die Reise. Sie können ihren Code selbständig gerne um weitere Funktionen erweitern.
Wie wäre es zum Beispiel mit der Subtraktion von zwei Zahlen \(a - b\)?
Was machen Sie wenn \(b > a\) ist?
Oder wie wäre es mit der Implementierung der Python-ähnlichen Listenmethoden:
Wir könnten auch eine Funktion schreiben, welche Listen sortiert.
Wie wäre es mit weiteren Datentypen wie bool, float oder ihrem ganz eigenen Datentyp?
In dieser Übung haben wir nur die Daten in den Speicher memory geschrieben.
Die Kontrolleinheit der CPU haben wir nicht modelliert.
Anstatt Register haben wir auf Python-Variablen und anstatt des Befehlszählers und der Sprungbefehlen, auf Python-Schleifen und if-Ausdrücke zurückgegriffen.
Wenn Sie mit Ihrem Modell noch näher an die reale CPU herankommen wollen, könnten Sie die Anweisungen ebenfalls in den Speicher packen.
Sie dürften nur die Hardware in Python-Befehle gießen, die auf der CPU auch tatsächlich vorhanden sind.
Damit hätten Sie nur eine endliche Menge von Variablen (je eine pro Register) keine Schleifen und nur if-Ausdrücke der Form:
if register1:
go_to(register2)
else:
go_to(register3)
Befehle könnten Sie als eigenen Datentyp modellieren und diese durch eine geeignete Codierung wiederum als Zahlen darstellen. Der Befehlszähler würde eine zentrale Rolle in Ihrem Modell spielen. Anfangs wäre der Berg von Problemen vor dem Sie stehen gigantisch. Doch wenn Sie sich erneut Schritt für Schritt voran kämpfen und den Berg in viele kleine Hügel aufteilen, kann auch das gelingen.
23.3.9. Memory Klasse#
Wir haben Ihnen alle Funktionen als Klassenmethoden in die Klasse Memory gepackt.
class Memory():
def __init__(self, size=1024):
self.ERROR_CODE = -1
self.SUCCESS_CODE = -2
self.name_to_dt = {'number': 0, 'char': 1, 'list': 2, 'addr': 3}
self.size = size
self.memory = [0 for _ in range(self.size)]
self.inuse = [False for _ in range(self.size)]
def to_data_type(self, name):
if name in self.name_to_dt:
return self.name_to_dt[name]
else:
return self.ERROR_CODE
def calc_bytes(self, data_type):
if data_type == self.to_data_type('number'):
return 3
if data_type == self.to_data_type('char'):
return 2
if data_type == self.to_data_type('addr'):
return 3
return self.ERROR_CODE
def number_to_byte(self, number):
return (number // 256, number % 256)
def to_number(self, byte1, byte2):
return byte1 * 256 + byte2
def char_to_byte(self, char):
return ord(char)
def to_char(self, byte):
return chr(byte)
def is_valid(self, addr):
return addr >= 0 and addr < len(self.memory)
def is_inuse(self, addr):
return self.inuse[addr]
def is_free(self, addr):
return self.is_valid(addr) and not self.is_inuse(addr)
def unfree(self, addr, n_bytes):
for i in range(n_bytes):
if self.is_valid(addr+i):
self.inuse[addr+i] = True
else:
return self.ERROR_CODE
return self.SUCCESS_CODE
def malloc(self, n_bytes):
addr = 0
count = 0
for b in self.inuse:
if not b:
count += 1
else:
addr += count + 1
count = 0
if count == n_bytes:
if self.unfree(addr, n_bytes):
return addr
else:
return self.ERROR_CODE
return self.ERROR_CODE
def mfree(self, addr, n_bytes):
for i in range(n_bytes):
if self.is_valid(addr+i):
self.inuse[addr+i] = False
else:
return self.ERROR_CODE
return self.SUCCESS_CODE
def calc_list_bytes(self, addr):
m = self.to_number(self.memory[addr+1], self.memory[addr+2])
n_bytes_element = self.calc_bytes(self.memory[addr+3]) - 1
return 4 + m * n_bytes_element
def alloc(self, data_type, value):
n_bytes = self.calc_bytes(data_type)
if n_bytes == self.ERROR_CODE:
return self.ERROR_CODE
addr = self.malloc(n_bytes)
if addr != self.ERROR_CODE:
self.memory[addr] = data_type
if data_type == self.to_data_type('number') or data_type == self.to_data_type('addr'):
byte_value = self.number_to_byte(value)
self.memory[addr+1] = byte_value[0]
self.memory[addr+2] = byte_value[1]
if data_type == self.to_data_type('char'):
self.memory[addr+1] = self.char_to_byte(value)
return addr
def alloc_list(self, data_type, n):
n_bytes = 4 + (self.calc_bytes(data_type)-1) * n
if data_type == self.to_data_type('list'):
return self.ERROR_CODE
# 1. alloc memory
addr = self.malloc(n_bytes)
# 2. initalize meta data (data type of the list and its elements and length of the list)
self.memory[addr] = self.to_data_type('list')
n_bytes = self.number_to_byte(n)
self.memory[addr+1] = n_bytes[0]
self.memory[addr+2] = n_bytes[1]
self.memory[addr+3] = data_type
return addr
def free(self, addr):
if self.is_valid(addr):
data_type = self.memory[addr]
if data_type == self.to_data_type('list'):
n_bytes = self.calc_list_bytes(addr)
else:
n_bytes = self.calc_bytes(data_type)
return self.mfree(addr, n_bytes)
return self.ERROR_CODE
def read_number(self, addr):
return self.to_number(self.memory[addr+1], self.memory[addr+2])
def add(self, addr1, addr2):
number1 = self.read_number(addr1)
number2 = self.read_number(addr2)
value = (number1 + number2) % (256**2)
addr = self.alloc(self.to_data_type('number'), value)
return addr
def list_len(self, addr):
return self.to_number(self.memory[addr+1], self.memory[addr+2])
def set_list_value(self, addr, index, value):
data_type = self.memory[addr+3]
m = self.calc_bytes(data_type)-1
mem_addr = addr + 4 + (m * index)
if data_type == self.to_data_type('number') or data_type == self.to_data_type('addr'):
byte_value = self.number_to_byte(value)
self.memory[mem_addr] = byte_value[0]
self.memory[mem_addr+1] = byte_value[1]
return self.SUCCESS_CODE
elif data_type == self.to_data_type('char'):
self.memory[mem_addr] = self.char_to_byte(value)
return self.SUCCESS_CODE
else:
return self.ERROR_CODE
def get_list_value(self, addr, index):
data_type = self.memory[addr+3]
m = self.calc_bytes(data_type)-1
#print(f"bytes: {m}")
#print(f"addr: {addr}")
mem_addr = addr + 4 + (m * index)
if data_type == self.to_data_type('number') or data_type == self.to_data_type('addr'):
return self.to_number(self.memory[mem_addr], self.memory[mem_addr+1])
elif data_type == self.to_data_type('char'):
return self.to_char(self.memory[mem_addr])
else:
return self.ERROR_CODE
def char_to_str(self, addr):
return self.to_char(self.memory[addr+1])
def number_to_str(self, addr):
return str(self.to_number(self.memory[addr+1], self.memory[addr+2]))
def list_to_str(self, mylist):
output = "["
length = self.list_len(mylist)
element_data_type = self.memory[mylist+3]
for i in range(length):
value = self.get_list_value(mylist, i)
if element_data_type == self.to_data_type('addr'):
output += self.mem_to_string(value)
elif element_data_type == self.to_data_type('char'):
output += value
elif element_data_type == self.to_data_type('number'):
output += str(value)
if i < length-1:
output += ", "
output += "]"
return output
def mem_to_string(self, addr):
output = ""
if self.is_valid(addr) and self.inuse[addr]:
data_type = self.memory[addr]
if data_type == self.to_data_type('char'):
output += self.char_to_str(addr)
elif data_type == self.to_data_type('number'):
output += self.number_to_str(addr)
elif data_type == self.to_data_type('list'):
output += self.list_to_str(addr)
elif data_type == self.to_data_type('addr'):
new_addr = self.read_number(addr)
output += self.mem_to_string(new_addr)
return output
def new_primitive_list(self, values, data_type):
length = len(values)
mylist = self.alloc_list(data_type, length)
# fill list
for i in range(length):
self.set_list_value(mylist, i, values[i])
return mylist
def get_data_type(self, value):
if type(value) == int:
return self.to_data_type('number')
if type(value) == str:
if len(value) == 1:
return self.to_data_type('char')
else:
return self.to_data_type('list')
def new_list(self, values):
length = len(values)
mylist = self.alloc_list(self.to_data_type('addr'), length)
for i in range(length):
element_data_type = self.get_data_type(values[i])
if element_data_type in [self.to_data_type('number'), self.to_data_type('char')]:
addr = self.alloc(element_data_type, values[i])
else:
addr = self.new_list(values[i])
self.set_list_value(mylist, i, addr)
return mylist
Wenn Sie die Klasse in die Datei mem.py packen, sieht der Code zur Verwendung wie folgt aus:
import mem
memory_object = mem.Memory(size=4048)
x = memory_object.alloc(to_data_type('number'), 4)
y = memory_object.alloc(to_data_type('number'), 130)
z = memory_object.add(x, y)
print(memory_object.mem_to_string(z))
numbers = memory_object.new_primitive_list([1,2,3,4,5,6], memory_object.to_data_type('number'))
print(memory_object.mem_to_string(numbers))
chars = memory_object.new_list("Hello World")
print(memory_object.mem_to_string(chars))
mixedlist = memory_object.new_list([1,2,"Hello World",4,5])
print(memory_object.mem_to_string(mixedlist))
mylist = memory_object.new_list([1, 2, 'A', [[1, 2], 3, 4], "Hello World"])
print(memory_object.mem_to_string(mylist))
134
[1, 2, 3, 4, 5, 6]
[H, e, l, l, o, , W, o, r, l, d]
[1, 2, [H, e, l, l, o, , W, o, r, l, d], 4, 5]
[1, 2, A, [[1, 2], 3, 4], [H, e, l, l, o, , W, o, r, l, d]]
23.4. Was soll das alles?#
Diese Übung scheint absonderlich.
Wir haben uns um viel Python-Funktionalität beraubt, um diese dann wieder zu implementieren.
Was soll das alles?
Mit dieser Übung wollten wir Ihnen zeigen, wie viel uns Python und andere Hochsprachen abnehmen und was eigentlich hinter den kurzen und überaus mächtigen Befehlen steckt.
Schreiben Sie in Python zum Beispiel:
mylist = [1,2,"Hello World",4,5]
mylist
[1, 2, 'Hello World', 4, 5]
passiert im Hintergrund eine ganze Menge und unsere Funktion
memory, inuse = initialize(1024)
mylist = new_list([1,2,"Hello World",4,5], memory, inuse)
print(mem_to_string(mylist, memory, inuse))
[1, 2, [H, e, l, l, o, , W, o, r, l, d], 4, 5]
schildert einen Teil davon. Zunächst einmal gibt es so etwas wie Datentypen. Ein Element eines Datentyps benötigt einen bestimmten (nicht variablen) Speicherbereich. Nur deshalb können wir Listenelemente direkt adressieren! Listen die Elemente unterschiedlicher Datentypen enthalten, enthalten Adressen (Zeiger) auf jene Elemente.
Speicher muss reserviert und wieder freigegeben werden. Es reicht nicht nur den Wert einer Variablen in den Speicher zu schreiben. Der Datentyp und andere Informationen werden ebenfalls abgelegt.
Wir konnten nur ein Stück weit näher an die Maschine herankommen.
Auch haben wir uns kaum um die Fehlerbehandlung gekümmert.
Was passiert zum Beispiel wenn der Speicher voll belegt ist?
Was passiert wenn eine Adresse addr1 auf eine andere Adresse addr2 zeigt und diese wiederum auf addr1 zeigt?
Wie stellen wir fest, dass keine Adresse mehr auf einen bestimmten Speicherbereich zeigt?
Wenn Sie der Übung folgen konnten, haben Sie ihr Verständnis der Programmausführung auf einem Computer geschärft. Sie haben aus primitiven Mitteln (einem linearen Speicher aus Zahlen (0 bis 255)) komplexe Strukturen (mehrdimensionale Listen) und Manipulationen errichtet. Im Endeffekt haben Sie einen kleinen Compiler geschrieben, der Ihnen den Befehl
memory, inuse = initialize(1024)
mylist = new_list([1,2,"Hello World",4,5], memory, inuse)
print(mem_to_string(mylist, memory, inuse))
[1, 2, [H, e, l, l, o, , W, o, r, l, d], 4, 5]
in eine Folge von maschinennäheren Befehlen umwandelt.
Adressen bzw. Zeiger auf andere Speicherobjekte werden Ihnen in Ihrer Programmierlaufbahn immer wieder begegnen.
Sie sind ein essenzielles Konzept der Programmierung, welches Sie auch bei der Programmierung Python kennen und verstehen sollten.
Sollten Sie je mit einer Sprache in Kontakt kommen in der Sie den Speicher selbst verwalten müssen (z.B. C/C++), so haben Sie hierfür eine erste Verständnisgrundlage.
Exercise 23.21 (Speicherverwaltung in C)
Können Sie erraten welche Auswirkungen folgender C-Code hat?
ptr = (float*) malloc(100 * sizeof(float));
...
free(ptr);
Solution to Exercise 23.21 (Speicherverwaltung in C)
Die erste Zeile allokiert einen Speicher für ein Array (Liste) aus Fließkommazahlen (float) der größe 100.
ptr ist der Zeiger der auf das Array zeigt. free(ptr) gibt den Speicher des Arrays frei.
Im Übrigen würden Sie in C mit ptr[3] = 100.3 den Wert 100.3 an die Stelle 3 des Arrays schreiben und mit &ptr erhalten Sie die Speicheradresse des Zeigers.
Wir hoffen, dass Sie durch diese Übung den Komfort, den Ihnen die Hochsprachen bieten, zu schätzen lernen.